Privacy Risk Evaluation - Methodology and Application on Call Profiles in Pisa
Call profile re-identification
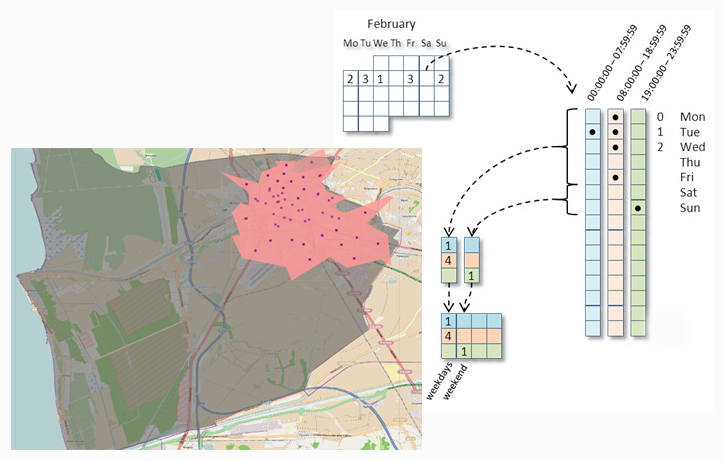
Profile can be seen as a spatio-temporal generalization of the CDR data of a user. Clearly, this form of data is more aggregated w.r.t. the CDR logs because it cannot reveal the history of the user movements, the number of calls and the exact day and time of each call. Moreover, this profile is constructed by considering a specific area such as a city therefore, it is impossible to infer where exactly the user went with a finer granularity. The only information that he can infer is that a specific user visited the city in a specific aggregated period. As an example, an attacker could understand that a given user went to Pisa during a specific week-end if the profiles that he was accessing are related to people in Pisa.
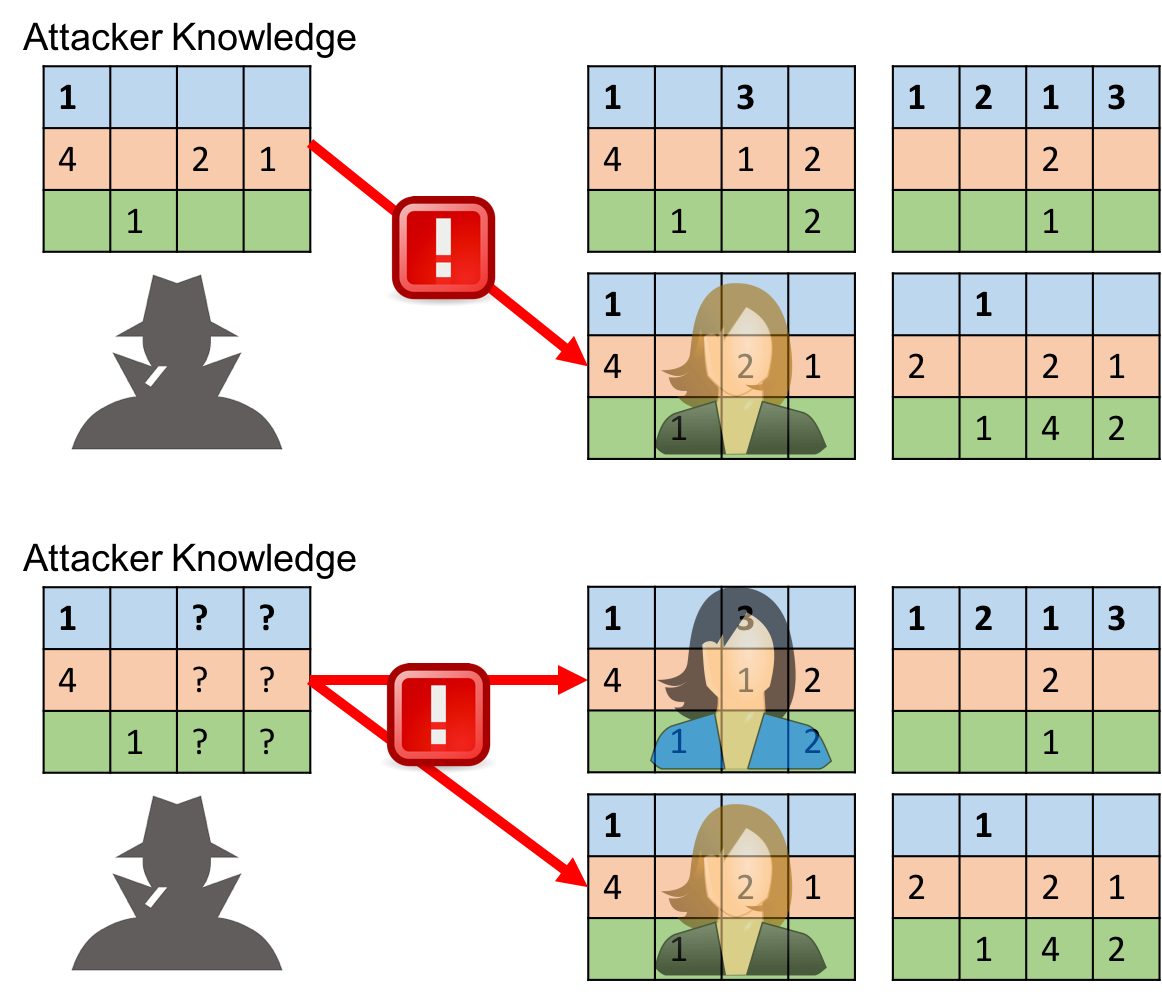
Given the methodology for extracting profiles, we can analyze the privacy risks of the users. In the case of Call Profiles the risk considered is the re-identification of the user: the probability of an attacker to discover the identity of an individual, having some external information on his target (partial or complete). In the firse example above the risk of re-identification is 100% because only 1 user in the set has a call profile which correspond to the attacker knowledge. In the second the risk is 50% because two of them correspond.
Evaluatin call profile risk in a real scenario
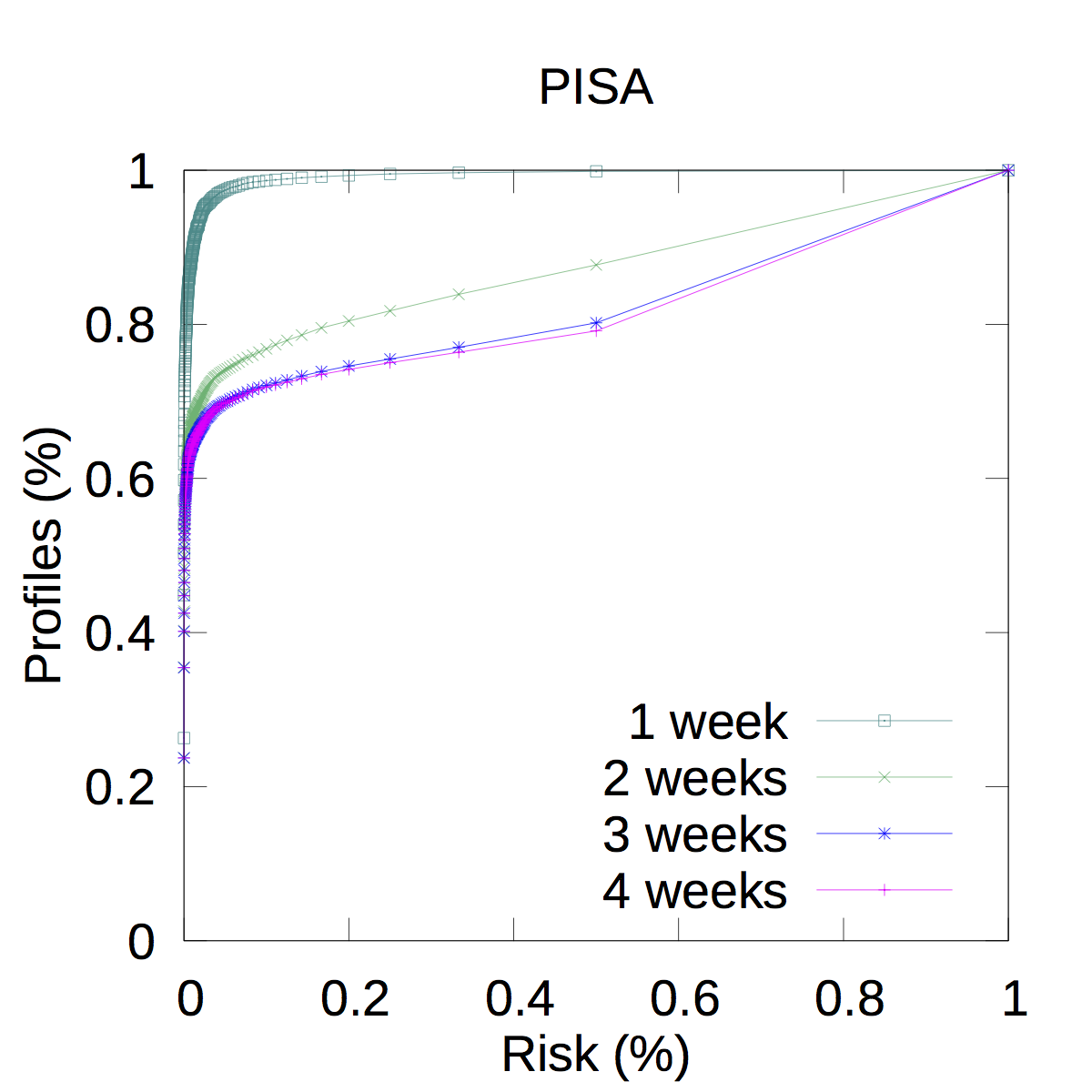
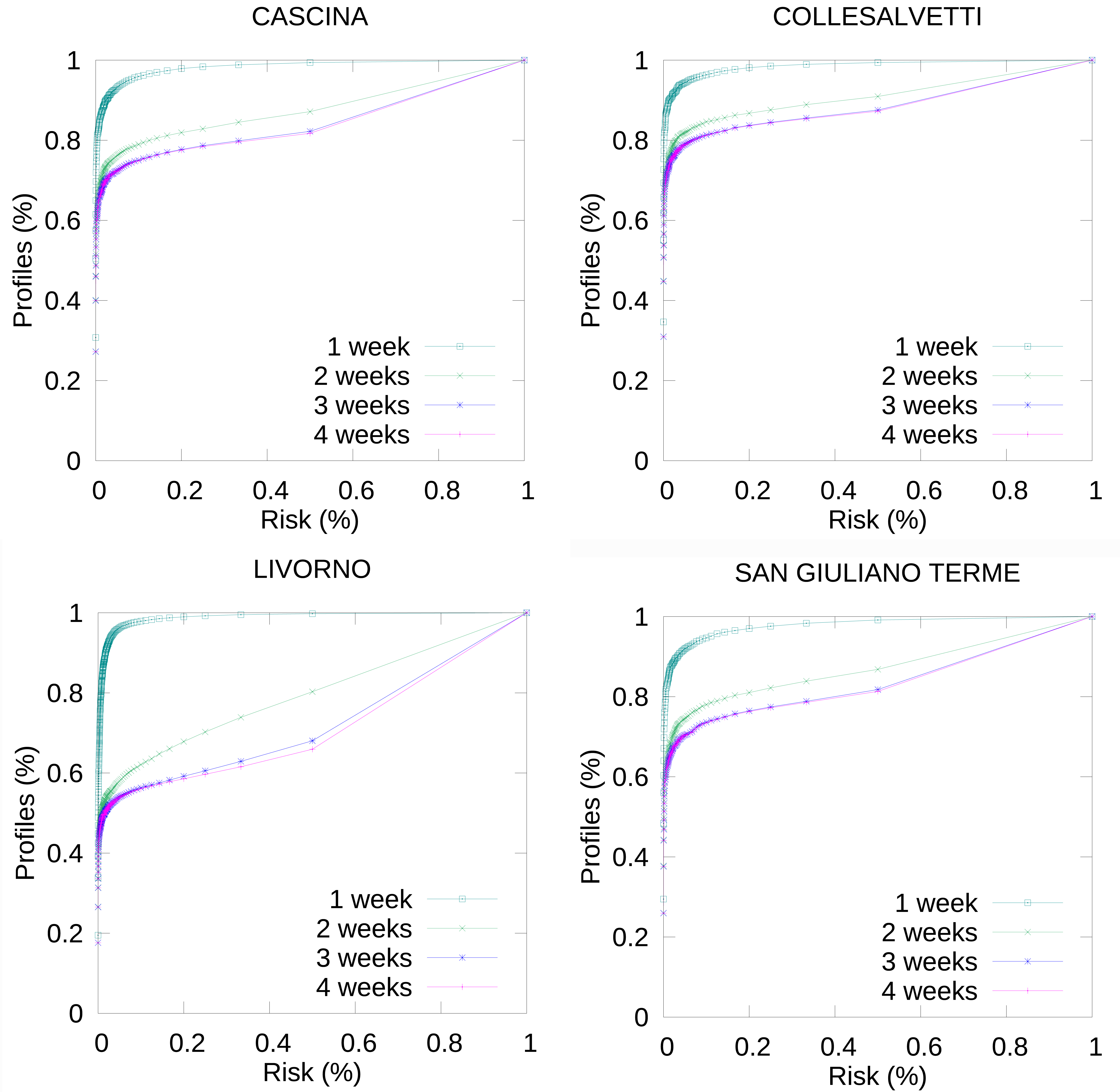
This plot shows the result of the simulation of attacks performed with a background knowledge of 1 week (the first one of November 2015) in the Pisa municipality. The cumulative highlight that in this case 11K users out of 181,866 (thus, corresponding to the 6% of the whole population) have a risk greater or equal than 0.2 (i.e., the set of possible candidates is composed by less than 5 profiles), whereas 19.5K (less than 11% of the population) have a risk greater or equal than 0.01 (the set is composed by less than 100 profiles). The same attack can be conducted varying the background knowledge. So, passing percentages also in the Y-axis we have that if we double the knowledge of the attacker (from 1 to 2 weeks), the overall risk is not surprisily higher. In this case the 33% of profiles has a risk greater or equal than 0.01, thus, the 67% of profiles (approximately 122K) are safe w.r.t. this threshold and could be released.The same reasoning can be done also increasing the background knowledge to 3 weeks, when the increment of risk is significantly lower: the risky profiles are 36%, so the safe ones are the 64% (about 116K in absolute values).The interesting fact is that increasing again the background knowledge to 4 weeks, the results are essentially the same.
These attack can be conducted also varying the spatial dimension, i.e., the municipality we assume the attacker knows. To give a better picture of the area around Pisa, we can simulate attacks in the bordering municipalities. As one can see, the results are very similar also for the other municipalities; the only exception is Livorno, where the risk mainly increase along with the background knowledge (for 4 weeks, the 51% of user has a risk greater or equals to 0.01).